How do companies like OpenAI, Anthropic, and xAI actually train their models? This page breaks down the architecture, algorithms, and training processes that power modern AI. Understanding this is essential for anyone looking to work at the frontier of AI development.
At its core, an LLM is a giant neural network trained to predict the next word (token) in a sequence. But the magic is in the details: the transformer architecture, the training data, the optimization algorithms, and the post-training alignment that makes these models useful and safe.
The Training Pipeline
Training a frontier LLM happens in distinct phases. Each phase builds on the previous one.
The result is a model that not only understands language patterns but actively tries to be helpful, harmless, and honest. The pretraining gives it knowledge and capability; the post-training gives it behavior and alignment.
The Transformer Architecture
The transformer is the foundational architecture behind all modern LLMs. Introduced in 2017 with the paper "Attention Is All You Need," it replaced older recurrent neural networks with a mechanism called self-attention.
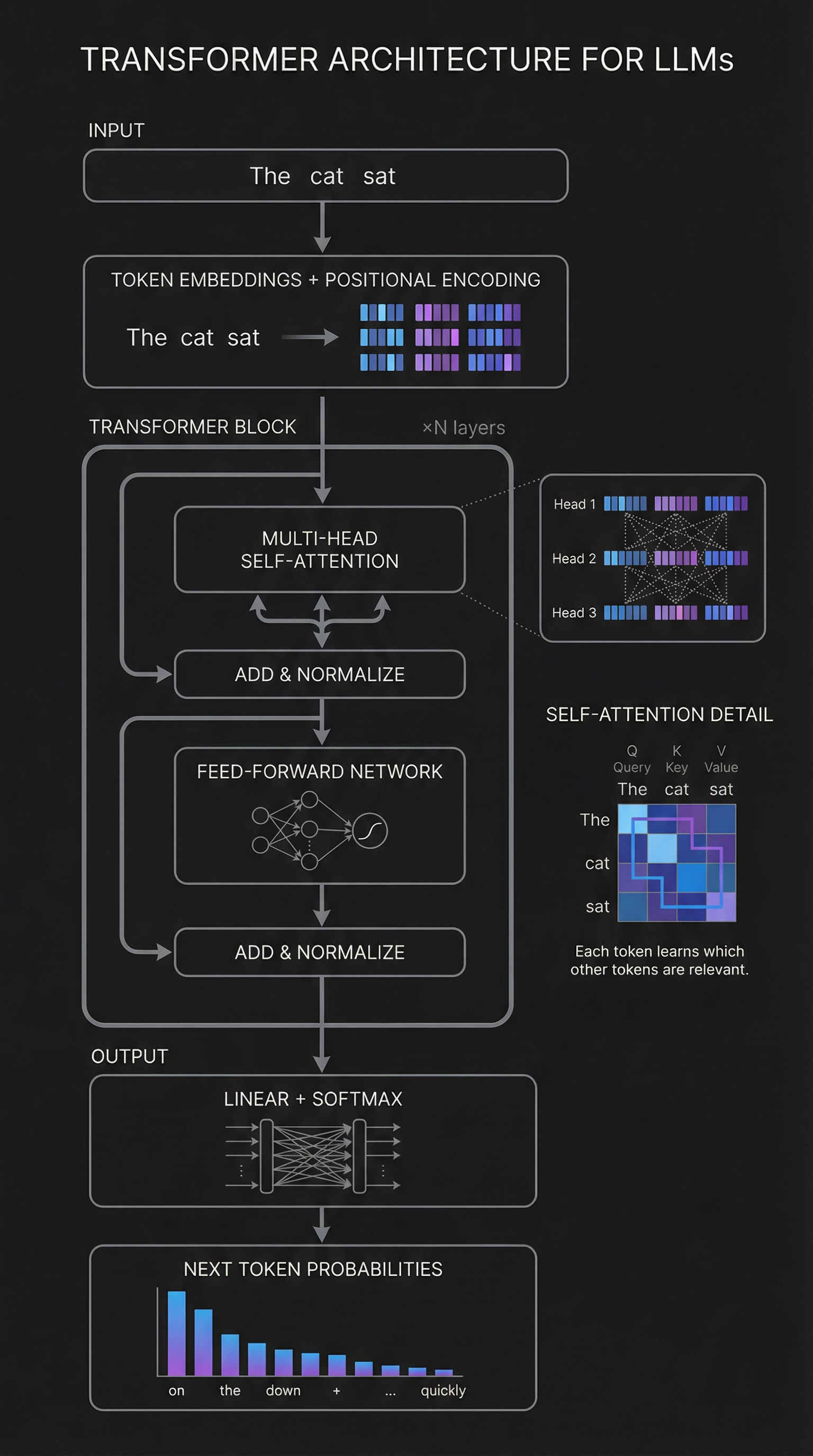
- Self-Attention — Each token can "attend" to every other token in the sequence. The model learns which tokens are relevant to each other, regardless of distance. This is how it understands context.
- Multi-Head Attention — Instead of one attention mechanism, transformers use multiple "heads" in parallel. Each head can learn different types of relationships (syntax, semantics, coreference).
- Feedforward Networks — After attention, each position passes through a feedforward neural network. This is where much of the "knowledge" is stored.
- Residual Connections — Skip connections add the input to the output of each layer. This helps gradients flow during training and allows the network to be very deep.
- Layer Normalization — Normalizes activations within each layer to stabilize training and improve convergence.
- Positional Encoding — Since attention has no inherent notion of order, position information is added to tell the model where each token appears in the sequence.
Decoder-only vs Encoder-Decoder: GPT, Claude, and Grok use decoder-only architectures optimized for text generation. They predict the next token autoregressively. Google's T5 and original BERT used encoder-decoder or encoder-only architectures for different tasks.
Tokenization & Embeddings
Before text enters the model, it must be converted into numbers. This happens in two steps: tokenization (breaking text into pieces) and embedding (converting pieces into vectors).
- Tokenization — Text is split into tokens, which are subword units. The word "understanding" might become ["under", "stand", "ing"]. Common algorithms: BPE (Byte Pair Encoding), SentencePiece, tiktoken.
- Vocabulary Size — Modern LLMs use vocabularies of 32K-100K+ tokens. Larger vocabularies mean more efficient encoding but more parameters. GPT-4 uses ~100K tokens; Claude uses ~100K.
- Token Embeddings — Each token ID maps to a learned vector (e.g., 4096 dimensions). These embeddings capture semantic meaning and are trained along with the model.
- Position Embeddings — Added to token embeddings to encode position. Modern models use RoPE (Rotary Position Embedding) which extends better to long sequences.
- Context Window — The maximum number of tokens the model can process at once. GPT-4 Turbo: 128K tokens. Claude 3: 200K tokens. Grok 4: 1M tokens.
Pretraining: Learning from the Internet
Pretraining is where the model learns language, facts, and reasoning from massive amounts of text. The objective is simple: predict the next token.
- Training Data — Trillions of tokens from the web (Common Crawl), books, Wikipedia, code (GitHub), scientific papers, and curated datasets. Data quality matters enormously.
- Objective Function — Cross-entropy loss on next-token prediction. The model outputs a probability distribution over all tokens; the loss penalizes putting low probability on the correct next token.
- Optimization — Adam or AdamW optimizer with learning rate warmup and decay. Training uses mixed-precision (FP16/BF16) to reduce memory and speed up computation.
- Parallelism — Training happens across thousands of GPUs using data parallelism (different batches), tensor parallelism (split layers), and pipeline parallelism (split model stages).
- Scaling Laws — Performance improves predictably with more parameters, data, and compute. Loss scales as a power law. Larger models are more sample-efficient.
Compute Scale: GPT-4 reportedly trained on ~25,000 A100 GPUs for months. Training a frontier model costs $50M-$100M+ in compute alone. Grok 4 trained on 200,000 GPUs in the Colossus cluster.
RLHF: Reinforcement Learning from Human Feedback
Pretraining produces a model that can predict text, but it doesn't know how to be helpful or follow instructions. RLHF aligns the model with human preferences.
The RLHF Process
- Step 1: Collect Demonstrations — Human labelers write examples of ideal responses to prompts. This creates a supervised fine-tuning (SFT) dataset.
- Step 2: Train SFT Model — Fine-tune the pretrained model on these demonstrations. The model learns the format and style of helpful responses.
- Step 3: Collect Comparisons — Show labelers two model responses to the same prompt. They rank which is better. This creates preference data.
- Step 4: Train Reward Model — Train a separate model to predict human preferences. Given a prompt and response, it outputs a scalar reward.
- Step 5: Optimize with RL — Use PPO (Proximal Policy Optimization) to fine-tune the SFT model to maximize reward while staying close to the original distribution (KL penalty).
Why it works: RLHF teaches the model that being helpful, honest, and harmless leads to higher reward. The model internalizes these preferences and generalizes them to new situations.
Tool Use: LLMs as the Brain, Not the Hands
Here's the key insight: LLMs don't actually do anything. They just generate text. The magic happens when you connect that text generation to real tools that execute actions.
Think of the LLM as a brain that understands your request and decides what to do. But the actual execution—reading files, running code, browsing the web, sending emails—happens through separate tools, functions, scripts, and APIs. The LLM is the interface; the tools are the hands.
How Tool Use Works
- Function Calling — The LLM is trained to output structured JSON that describes which tool to call and with what arguments. OpenAI calls this "function calling"; Anthropic calls it "tool use."
- Tool Definitions — You give the model a list of available tools with descriptions of what they do and what parameters they accept. The model learns to pick the right tool for each task.
- Execution Loop — The system executes the tool, captures the output, and feeds it back to the LLM. The model can then decide what to do next based on the result.
- Multi-step Reasoning — Complex tasks require multiple tool calls. The LLM plans, executes, observes, and iterates until the task is complete.
Examples of Tools
- File Operations — Read files, write files, search codebases, create directories
- Shell Commands — Run terminal commands, install packages, execute scripts
- Browser Automation — Navigate to URLs, click buttons, fill forms, take screenshots
- APIs — Call external services (GitHub, Slack, databases, email)
- Code Execution — Run Python/JavaScript in a sandbox to compute results
This is what makes Cursor powerful: The LLM understands your intent ("fix this bug"), then orchestrates tools to actually do it—reading your code, making edits, running tests, committing to git. The model is the decision-maker; the tools are the execution layer.
Agentic AI
When an LLM can autonomously use tools in a loop—planning, executing, observing results, and adapting—it becomes an agent. This is the frontier of AI right now.
- ReAct Pattern — Reason → Act → Observe → Repeat. The model thinks about what to do, takes an action, sees what happened, and continues.
- Planning — Advanced agents can break down complex tasks into subtasks and execute them systematically.
- Error Recovery — Good agents can detect when something went wrong and try a different approach.
- Memory — Agents can maintain state across interactions, remembering what they've done and learned.
MCP (Model Context Protocol): This is Anthropic's open standard for connecting LLMs to tools. Think of it like USB for AI—a universal way to plug capabilities into any model. Cursor uses MCP to connect to GitHub, Slack, browsers, and more.
How Different Companies Train
Each AI lab has developed unique training approaches that reflect their philosophy and research priorities.
OpenAI GPT Models
- InstructGPT / ChatGPT — Pioneered RLHF for instruction-following. SFT on human demonstrations, then RL with human preference data.
- GPT-4 — Mixture-of-Experts architecture (rumored). Massive scale pretraining followed by RLHF. Strong focus on capabilities and reasoning.
- o1 / o3 — Reasoning models trained with RL on chain-of-thought. The model learns to "think" step-by-step before answering.
Anthropic Claude
- Constitutional AI (CAI) — Instead of pure human feedback, Claude is trained with a "constitution" of principles. The model critiques and revises its own responses.
- RLAIF — Reinforcement Learning from AI Feedback. An AI evaluates responses against the constitution, reducing reliance on human labelers.
- Two-Phase CAI — (1) Supervised phase: model self-critiques and improves. (2) RL phase: AI-generated preferences train the reward model.
- Focus on Safety — Anthropic prioritizes harmlessness and honesty. Claude is designed to refuse harmful requests while explaining why.
xAI Grok
- Mixture-of-Experts (MoE) — Grok-1 uses 314B parameters with MoE, activating only a subset for each token. More efficient than dense models.
- Real-time Data — Trained with continuous ingestion from X (Twitter), giving it more current knowledge than competitors.
- Colossus Supercomputer — 200,000 GPUs for Grok 4 training. 10x more compute than Grok 3.
- Open Weights — Grok-1 weights were released publicly, unlike GPT and Claude.
Google Gemini
- Multimodal Native — Trained on text, images, audio, and video from the start, not just text with vision added later.
- TPU Training — Uses Google's custom TPU chips rather than NVIDIA GPUs. Different hardware optimization.
- Ultra Scale — Gemini Ultra reportedly used more compute than GPT-4. Google has massive infrastructure advantages.
LLaMA
- Open Source Focus — LLaMA models are released with weights, enabling the open-source community to build on top.
- Efficient Training — LLaMA 2 achieved competitive performance with less compute by focusing on data quality and longer training.
- Academic Friendly — Available for research, driving rapid innovation outside big labs.
Key Concepts to Understand
These are the terms and ideas you need to know to discuss LLM training intelligently.
- Parameters — The learnable weights in the neural network. GPT-4: ~1.7 trillion (rumored). Claude 3 Opus: ~200B. More parameters = more capacity.
- FLOPs — Floating point operations. A measure of compute. Frontier models train with 10^24+ FLOPs.
- Perplexity — A measure of how well the model predicts text. Lower is better. Exponential of average cross-entropy loss.
- Gradient Descent — The optimization algorithm that updates parameters to minimize loss. Backpropagation computes gradients through the network.
- Batch Size — How many examples are processed together before updating weights. Larger batches are more efficient on GPUs.
- Learning Rate — How big a step to take when updating weights. Too high = unstable. Too low = slow convergence.
- Overfitting — When the model memorizes training data instead of generalizing. Regularization and data diversity prevent this.
- Emergent Abilities — Capabilities that appear suddenly at scale, like in-context learning, chain-of-thought reasoning, and tool use.
- Chinchilla Scaling — DeepMind's finding that models should be trained on ~20 tokens per parameter for optimal compute efficiency.
- KV Cache — Key-value cache that stores intermediate computations during inference to avoid redundant work. Critical for fast generation.
What Cursor Does
Cursor isn't training foundation models from scratch. Instead, they're doing applied AI research that makes these models dramatically more useful for coding.
- Model Orchestration — Cursor routes queries to different models (Claude, GPT-4) based on task type. They optimize for speed, quality, and cost.
- Custom Fine-tuning — Cursor trains specialized models for code completion, error fixing, and codebase understanding.
- Context Engineering — Massive focus on what context to provide the model. Semantic search over codebases, relevant file detection, diff context.
- Tool Use — Training models to use tools: file editing, terminal commands, browser automation. This is agentic AI.
- Inference Optimization — Fast response times require optimized serving infrastructure. Speculative decoding, caching, batching.
Why this matters for jobs: Cursor is hiring for ML engineering, infrastructure, and product roles that focus on applying frontier models to real problems. You don't need to know how to pretrain GPT-4, but you do need to understand how these models work and how to make them useful.
Resources for Going Deeper
Papers
- Attention Is All You Need — The original transformer paper (2017)
- Training language models to follow instructions with human feedback — InstructGPT / RLHF (OpenAI)
- Constitutional AI — Anthropic's alignment approach
- Scaling Laws for Neural Language Models — Kaplan et al.
- Training Compute-Optimal Large Language Models — Chinchilla scaling (DeepMind)
Videos & Courses
- Andrej Karpathy: Let's build GPT from scratch
- Karpathy: Neural Networks: Zero to Hero
- Karpathy: Let's build the GPT Tokenizer